新闻动态
kaiyun官方网站 kaiyun官方网站
kaiyun官方网站
最近LeCun又发新作,依然是崩溃问题,依然是自监督,此次提倡了一个新的正则化措施:方差正则,可以灵验属目编码崩溃,还能进步重构质地,一张显卡就能训!
神经网罗中有一类学习相称受参谋东谈主员的深爱,那便是自监督学习(self-supervised learning SSL)。
独一给实足多的数据,自监督学习冒昧在十足不需要东谈主工标注的情况下,学习到文本、图像的表征,而且数据量越大、模子参数目越大,效用越好。
自监督学习的责任旨趣也很简便:举例应用场景是图片的话,咱们可以把SSL模子的输入和输出齐建造为消释张图片,中间加入一个荫藏层,然后开训!
一个最简便的自编码器AutoEncoder就弄好了。
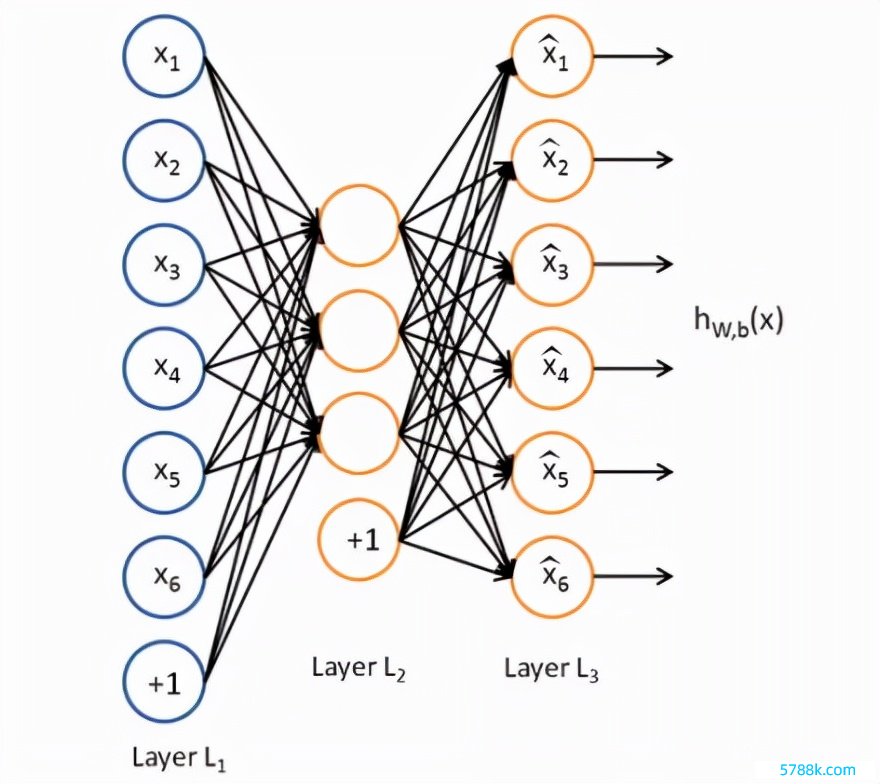
频繁来说荫藏层的神经元数目是要小于输入图片的,这么现实后,自编码器的中间荫藏层就可以行为图片的表征向量,因为现实进程的打算便是仅用该荫藏向量即可收复图片。
自编码器起原提倡是基于降维的念念想,关联词当隐层节点比输入节点多时,自编码器就会失去自动学习样本特征的才气,此时就需要对荫藏层节点进行一定的经管。
寥落自编码器应时而生,经管的起点来自于:高维而寥落的抒发是好的。是以只需要对荫藏层节点进行寥落性经管即可。
常用的寥落编码口头虽然是L1正则。
最近LeCun提倡了一种新的寥落编码条约可以属目编码的崩溃,而不需要对解码器进行正则化处理。新的编码条约径直对编码进行正则化,使每个潜码要素(latent code component)在一组给定的输入的寥落示意上具有大于固定阈值的方差。

论文:https://arxiv.org/abs/2112.09214
开源代码:https://github.com/kevtimova/deep-sparse
此外,参谋东谈主员还探索了何如期骗多层解码器来灵验现实寥落编码系统的措施,可以比线性字典(linear dictionary)模拟更复杂的考虑。
在对MNIST和当然图像块(natural image patch)的实验中,实验闭幕标明使用新措施学习到的解码器在线性和多层情况下齐有可解说的特征。
与使用线性字典的自动编码器比较,使用方差正则化措施现实的具有多层解码器的寥落自动编码器可以产生更高质地的重建,也标明方差正则化措施获得的寥落表征在低数据量下的去噪和分类等卑劣任务中很有用。
论文中LeCun的作家单元亦然从FAIR改名为Meta AI Research(MAIR)。
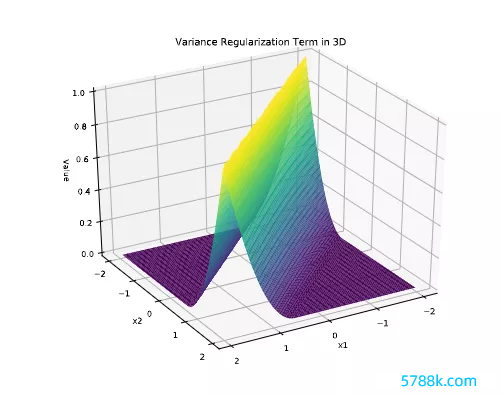
方差正则给定一个输入y和一个固定的解码器D,参谋东谈主员使用FISTA算法(近似梯度措施ISTA的快速版)进行推理来找到一个寥落编码z*,获得的z*可以使用D中的元素最佳地重建输入y。
解码器D的权重是通过最小化输入y和从z∗狡计出的重构y之间的平均渊博毛病(MSE)来现实获得的。
编码器E的权重则是通过瞻望FISTA的输出z∗获得。
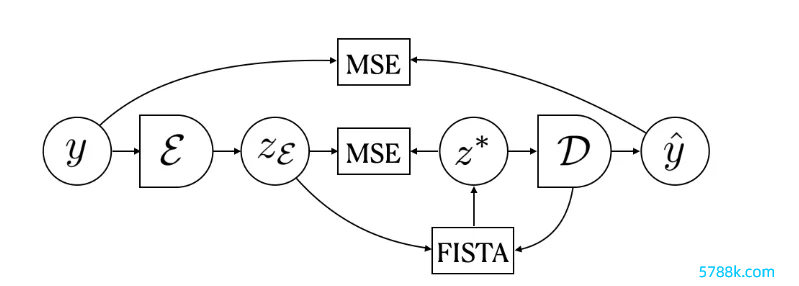
为了属目潜码的L1正则崩溃,参谋东谈主员加入了一个狂放条目,确保每个潜码方差大于事前设定的阈值。主要竣事措施便是对能量函数加入一个正则化项,从而冒昧促使通盘潜码重量的方差保捏在预设的阈值以上。
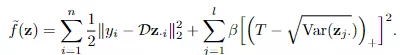
更具体地说,参谋东谈主员修改了推理进程中的打算函数来最小化能量。
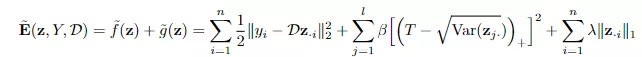
其中hinge项与L1管理项相对消行为新的正则化项,新的方程可以饱读动每个潜藏代码要素的方差保捏在的阈值以上,从而可以属目潜码的L1正则崩溃,进而无需对解码器权重进行正则化。
重构项乞降之后的梯度和潜码z对应。
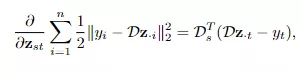
关于线性解码器来说,尽管hinge项不是光滑的凸函数,但梯度是一条线(line)意味着hinge项在局部推崇得像一个凸二次函数。
现实进程中,参谋东谈主员将编码器E与解码器D同期现实来瞻望FISTA推理狡计的寥落编码。
同期现实的第一个原因是为了幸免在解码器现实完成后使用批量统计来狡计编码。事实上,应该可认为不同的输入独随即狡计编码。
第二个原因是为了减少推理时辰。编码器息争码器的现实完成后,编码器可以径直狡计输入的寥落示意,这么就不需要用FISTA进行推理,即编码器可以进行amoritized推理。
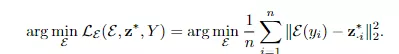
编码器的正则项可以促使FISTA找到可以被编码器学习到的编码。在实验建造中,编码器的瞻望频繁被视为常数(constants),用作FIST编码的启动值。
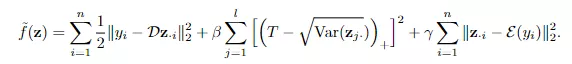
要是编码器提供了一个好的启动值,则可以通过减少FISTA迭代的次数来减少推理时辰。
实验建造实验中的编码器为一个LISTA(Learned ISTA)编码器,它的遐想是为了师法ISTA推理的输出,相通于一个递归神经网罗。编码器由两个全连结层,一个偏置项,以及ReLU激活函数构成。

线性解码器的参数简便地说是一个线性变换,将编码映射到输入数据的重构维度上,在线性变换中莫得偏置项。
在非线性解码器的情况下,使用一个大小为m的荫藏层和大小为l的输入层(潜码的size)的全连结网罗,使用ReLU行为荫藏层的激活函数。将输入代码映射到隐含表征的层中有一个偏置项,而将隐含表征映射到输出的层莫得偏置项。
在推理进程中,编码z被狂放为非负值。MNIST实验中潜码的维度为128,在ImageNet patch的实验中则是256,当batch size为250时,关于VDL中每个潜要素(latent component)的方差的正则化项来说是实足大的。
将FISTA的最大迭代次数K建造为200次,依然足以竣事一个效用可以的重构模子了。
在自编码器现实中,参谋东谈主员建造MNIST的epoch为200,image patch则为100。在SDL和SDL-NL实验中,将解码器的全连结层W、W1和W2中的列的L2正则固定为1,并保存输出平均能量最低的自编码器。
参谋东谈主员还对SDL-NL和VDL-NL模子中的偏置项b1以及LISTA编码器中的偏置项b加多了权重衰减,以属目其正则化项无穷延迟。
模子的现实只需要一块NVIDIA RTX 8000 GPU卡,而且通盘实验的运行时辰齐在24小时以内。
实验闭幕可以看到,关于两个SDL和两个VDL的字典元素(dictionary elements)来说,在寥落度λ较低的情况下(0.001, 0.005)解码器似乎可以学到场合、笔划,以至是是数字图形中的一部分。

跟着λ值的提高,生成的图像也越来越像一个完满的数字,完成了从笔划到数字的演化。
在重构质地上,SDL和VDL模子的编码器的弧线显露了由未激活编码(值为0)要素的平均百分比掂量的寥落进程和由平均PSNR掂量的重建质地之间的量度。
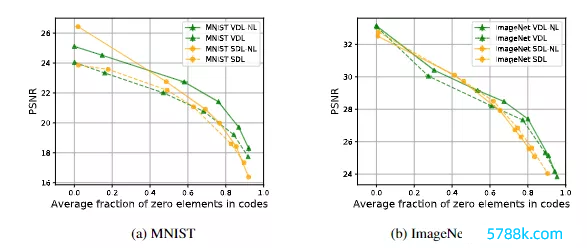
在5个无意种子上的测试集所掂量的重建质地和预期相符,较高的寥落度会导致更差的重建效用,但用文中提倡的方差正则化措施现实出来的模子则会比SDL 模子在更高的寥落进程下产生更好的重建效用,从而阐述了方差正则化如实是灵验的。
Powered by kaiyun网页登陆入口 @2013-2022 RSS地图 HTML地图